Supercharging file-based content with GraphQL
April 29, 2021
By Jeff See
Today we want to introduce you to the Tina GraphQL gateway that brings reliability to Git-based content management. It's an essential piece to provide a robust structured content, while your content remains fully portable.
Overcoming the limitations of the filesystem
Using the filesystem for website content has been a mainstay of the web development ecosystem for years. The ability to ship your entire website in one fell swoop and roll anything back with thanks to Git has made this a popular and efficient way to get things done with confidence.
On the other hand, the open nature of using files for content can lead to headaches. Content Management Systems (CMS) have always provided confidence in another way — knowing that your content's shape won't change out from underneath you. The scary (and powerful) thing about using the filesystem is that there's no layer to ensure that you're getting the content that you expect. It's a trade-off that has many valid use-cases, but just as many foot guns.
Let's take an example
We're going to use the Next.js blog starter to demonstrate some of the problems with file-based content and how we hope to solve them. If you'd like to follow along you can fork this repository and start with the branch called start. To skip ahead to the final solution check out the add-tina-gql branch.
Our content structure
This app sources its content from Markdown files in a folder called _posts:
- _posts
- dynamic-routing.md
- hello-world.md
- preview.md
- pages
- index.js # lists the blog posts
- posts
- [slug].js # dynamically shows the appropriate blog postOn the home page we get each post from the _posts directory and sort them by date before showing them with our getAllPosts function:
export function getAllPosts(fields = []) {
const slugs = getPostSlugs()
const posts = slugs
.map(slug => getPostBySlug(slug, fields))
// sort posts by date in descending order
.sort((post1, post2) => (post1.date > post2.date ? -1 : 1))
return posts
}And the result:
Demo: ➡️ Start following along
File-based content is simple
What we have so far is great, since our changes are stored in Git we know that if we made a mistake we will be able to easily roll it back to a previous version. But as the complexity of our content increases things become less straightforward.
To demonstrate that, let's first look at how our content is structured. The "Dynamic Routing and Static Generation" blog post looks like this:
---
title: 'Dynamic Routing and Static Generation'
excerpt: 'Lorem ...'
coverImage: '/assets/blog/dynamic-routing/cover.jpg'
date: '2020-03-16T05:35:07.322Z'
author:
name: JJ Kasper
picture: '/assets/blog/authors/jj.jpeg'
ogImage:
url: '/assets/blog/dynamic-routing/cover.jpg'
---
Lorem ipsum dolor sit amet ...Let's expand on this structure by adding the ability to filter which blog posts show up on the home page. To do that we add a new boolean value to each post called featured.
---
title: 'Dynamic Routing and Static Generation'
excerpt: 'Lorem ...'
coverImage: '/assets/blog/dynamic-routing/cover.jpg'
date: '2020-03-16T05:35:07.322Z'
author:
name: JJ Kasper
picture: '/assets/blog/authors/jj.jpeg'
ogImage:
url: '/assets/blog/dynamic-routing/cover.jpg'
featured: true
---
Lorem ipsum dolor sit amet ...Now we can update our getAllPosts function accordingly:
export function getAllPosts(fields = []) {
const slugs = getPostSlugs();
const posts = slugs
.map((slug) => getPostBySlug(slug, fields))
// sort posts by date in descending order
.sort((post1, post2) => (post1.date > post2.date ? -1 : 1))
+ .filter((post) => post.featured);
return posts
}Let's add a new post to test this out, this one won't be featured:
---
title: 'Why Tina is Great'
excerpt: 'Lorem ...'
coverImage: '/assets/blog/dynamic-routing/cover.jpg'
date: '2021-04-25T05:35:07.322Z'
author:
name: JJ Kasper
picture: '/assets/blog/authors/jj.jpeg'
ogImage:
url: '/assets/blog/dynamic-routing/cover.jpg'
featured: 'false'
---
Lorem ipsum dolor sit amet ...Woops, look who's showing up on our home page:
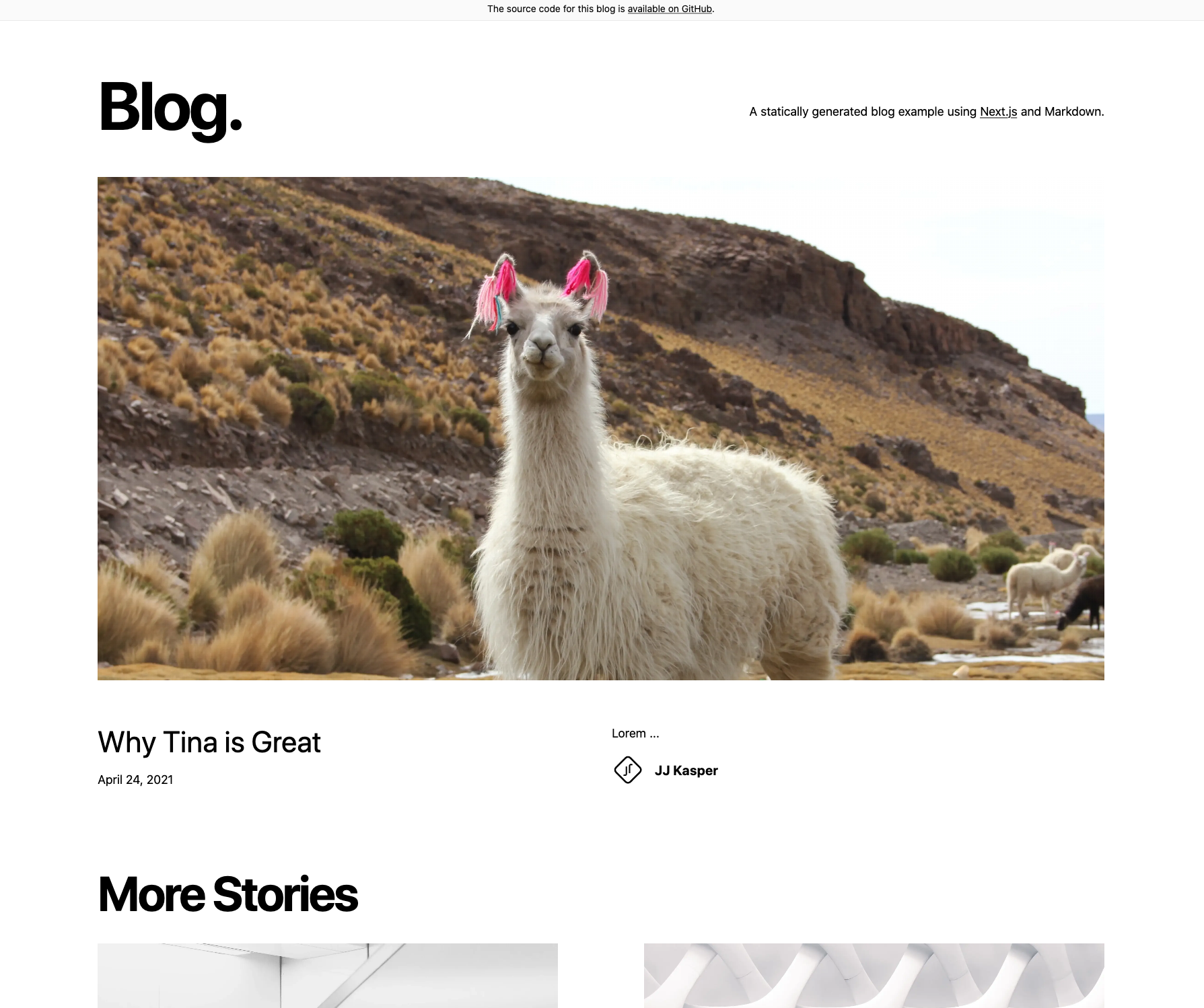
Can you spot the issue? We accidentally set featured to "false" instead of false! We made it a string, not a boolean.
Demo: 👀 Spot our mistakes.
If we had been using a CMS this probably wouldn't have happened. Most of them require that the shape of your content is well-defined. While these kinds of issues are painful, there's a lot more that CMSs do for us that we don't get from the filesystem — you may have noticed something else about the shape of our content that doesn't feel quite right…
Relationships: it's complicated
Let's look at the data from our new blog post again:
---
title: "Why Tina is Great"
excerpt: "Lorem ..."
coverImage: "/assets/blog/dynamic-routing/cover.jpg"
date: "2021-04-25T05:35:07.322Z"
author:
name: JJ Kasper
picture: "/assets/blog/authors/jj.jpeg"
ogImage:
url: "/assets/blog/dynamic-routing/cover.jpg"
featured: "false"
---
Lorem ipsum dolor sit amet…The author content is the same over in the "Dynamic Routing and Static Generation" post. If JJ wanted to change his picture he will need to update it on every post he's written. Sounds like something a CMS would solve with a content relationship, JJ should ideally be an author who has many posts. To solve this with our file-based content we could split the author data into its own file and place a reference to that author's filename in the post structure:
author: _authors/jj.mdBut now we have to update our data-fetching logic so that whenever it comes across the author field in a post it knows to make an additional request for that data. This is pretty cumbersome, and again — as complexity grows this type of logic quickly becomes untenable. With a CMS SDK or GraphQL API we'd be able to do this sort of thing easily, and we'd have confidence that a document can't be deleted if it's being referenced from another document.
Demo: Check out the diff to see how we're awkwardly making use of a separate
authorfile.
Content Management Systems: Reliable? Yes. Portable? No.
Headless CMSs are a great way to maintain full control over your frontend code while offloading issues like those mentioned above to a more robust content layer. But when you hand your content over to a CMS you lose the power of Git that comes built-in with file-based content.
With a CMS, when you make a change to the shape of your content you also need to coordinate that new shape with your code, and you need to make sure that all of your existing content has been updated accordingly.
Most CMSs have come up with various ways to help with this: separate sandbox environments, preview APIs, and migration SDK scripts — all of which carry their own set of headaches. None of this is necessary with file-based content, everything moves and changes together. So what if we could bring the robust features of a headless CMS to your local filesystem? What might that look like?
Meet Tina Content API
Today we're introducing a tool that marries the power of a headless CMS with the convenience and portability of file-based content. The Tina Content API is a GraphQL service that sources content from your local filesystem. It will soon be available via Tina Cloud, which connects to your GitHub repository to offer an identical, cloud-based, headless API.
Tina Cloud is currently in public beta, sign up to get started with Next.js.
To get a sense for how this works, let's make some tweaks to the blog demo.
First let's install Tina CLI:
yarn add tina-graphql-gateway-cliNow let's add a schema so the API knows exactly what kind of shape to build for your content:
mkdir .tina && touch .tina/schema.ts// `.tina/schema.ts`
import { defineSchema } from 'tina-graphql-gateway-cli'
export default defineSchema({
collections: [
{
label: 'Posts',
name: 'post',
/*
* Indicates where to save this kind of content (eg. the "_posts" folder)
*/
path: '_posts',
templates: [
{
label: 'Simple',
name: 'simple_post',
fields: [
{
type: 'text',
label: 'Title',
name: 'title',
},
{
type: 'text',
label: 'Excerpt',
name: 'excerpt',
},
{
type: 'text',
label: 'Cover Image',
name: 'coverImage',
},
{
type: 'text',
label: 'Date',
name: 'date',
},
{
// We indicate the author is a "reference"
// to another document
type: 'reference',
name: 'author',
label: 'Author',
collection: 'author',
},
{
type: 'group',
name: 'ogImage',
label: 'Open Graph Image',
fields: [
{
type: 'text',
label: 'URL',
name: 'url',
},
],
},
{
type: 'toggle',
label: 'Featured',
name: 'featured',
},
],
},
],
},
{
name: 'author',
label: 'Authors',
path: '_authors',
templates: [
{
label: 'Author',
name: 'author',
fields: [
{
type: 'text',
label: 'Name',
name: 'name',
},
{
name: 'picture',
label: 'Picture',
type: 'text',
},
],
},
],
},
],
})Notice that we're referencing the authors section from the post.author field
Next we replace the dev command to start the GraphQL server in tandem with our Next.js app:
"scripts": {
"dev": "yarn tina-gql server:start -c \"next dev\"",
...
},Demo: Here's the changes we've made so far. Check out the
add-tina-graphqlbranch to pick up from this point.
Run the dev command, you can see that we now have a local GraphQL server listening on port 4001 along with some information about auto-generated configuration files:
Started Filesystem GraphQL server on port: 4001
Generating Tina config
Tina config ======> /.tina/__generated__/config
Typescript types => /.tina/__generated__/types.ts
GraphQL types ====> /.tina/__generated__/schema.gql
ready - started server on 0.0.0.0:3000, url: http://localhost:3000Let's test it out:
💡Tip: if you have a GraphQL client like Altair you can explore the API by pointing it to http://localhost:4001/graphql
# Point your request to http://localhost:4001/graphql
{
getPostList {
data {
... on SimplePost_Doc_Data {
title
}
}
}
}And here is the result:
{
"errors": [
{
"message": "Unexpected value of type string for boolean value",
"path": ["getPostList"]
}
],
...
}This error is coming from our old friend featured: "false". This is exactly the kind of assurance you'd get from a CMS, but without any of the overhead. After fixing the issue, we get what we expected:
{
"data": {
"getPostList": [
{
"data": {
"title": "Dynamic Routing and Static Generation"
}
},
... # truncated
]
}
}We can use GraphQL to replace all of our bespoke filesystem data-fetching logic and rest assured that the data we get back will be exactly what we expect it to be.
query BlogPostQuery($relativePath: String!) {
getPostDocument(relativePath: $relativePath) {
data {
... on SimplePost_Doc_Data {
title
excerpt
date
coverImage
author {
data {
... on Author_Doc_Data {
name
picture
}
}
}
ogImage {
url
}
featured
_body
}
}
}
}Demo: View the changes we made to add Tina GraphQL
To be continued
Being able to work locally with GraphQL is a first step to help us bring the capabilities of a full-fledged CMS to the filesystem. Tina Cloud will offer the same great experience through a hosted headless API. In the coming weeks we'll continue sharing more about how this API works with TinaCMS to bring visual content management to your website with minimal overhead.
Take a look at the demo we just went through, see if you can expand on it and share your progress with us!
Last Edited: April 29, 2021